신경망을 훈련할 때 가장 자주 사용되는 알고리즘은 역전파(back propagation)입니다. 이 알고리즘에서는 주어진 매개변수에 대해 손실함수의 기울기(gradient)에 따라 모델의 가중치(매개변수)가 조정됩니다.
이러한 기울기를 계산하기 위해 PyTorch는 `torch.autograd`라는 내장 미분 엔진을 갖추고 있습니다. 이는 어떠한 계산 그래프에 대해서도 자동으로 기울기를 계산할 수 있는 기능을 지원합니다.
간단한 신경망 예제
다음은 입력 `x`, 매개변수 `w` 및 `b`, 그리고 어떤 손실 함수를 사용하는 가장 간단한 한 층의 신경망입니다. PyTorch에서는 다음과 같이 정의할 수 있습니다:
import torch
# 입력 텐서
x = torch.ones(5) # 크기가 5인 텐서, 모든 요소가 1
# 예상 출력
y = torch.zeros(3) # 크기가 3인 텐서, 모든 요소가 0
# 가중치 w와 편향 b, 미분 계산을 위해 requires_grad=True로 설정
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
# 선형 변환 수행 및 편향 추가
z = torch.matmul(x, w) + b
# 손실 함수 적용
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
이 코드에서 `torch.matmul()`은 두 텐서의 행렬 곱을 수행합니다. 여기서는 입력 `x`와 가중치 `w`의 행렬 곱을 계산한 후 편향 `b`를 더합니다. 그 결과로 얻어진 `z`를 바이너리 크로스 엔트로피 손실 함수에 입력하여 손실 값을 계산합니다.
손실에 대한 기울기 계산
PyTorch의 `torch.autograd`는 이 손실 값에 대한 기울기를 자동으로 계산할 수 있게 해 줍니다. 이는 모델 학습 시 매개변수의 최적화에 필수적인 정보입니다. 손실에 대한 기울기를 계산하려면 `loss.backward()`를 호출하기만 하면 됩니다. 이 호출은 `w`와 `b`에 저장된 `grad` 속성에 각각의 기울기를 저장합니다.
# 손실에 대한 기울기 계산
loss.backward()
# 가중치 w와 편향 b의 기울기 출력
print(f"Gradient of w: {w.grad}")
print(f"Gradient of b: {b.grad}")
이렇게 `torch.autograd`를 사용함으로써, 복잡한 수식의 미분 계산을 자동으로 처리하고, 신경망의 훈련 과정을 효율적으로 진행할 수 있습니다.
텐서, 함수, 그리고 계산 그래프
PyTorch에서는 각 텐서와 이를 이용해 수행되는 연산들로부터 계산 그래프(computational graph)가 구성됩니다. 계산 그래프는 네트워크의 연산과 매개변수 간의 관계를 나타내며, 이를 통해 자동 미분이 가능해집니다.
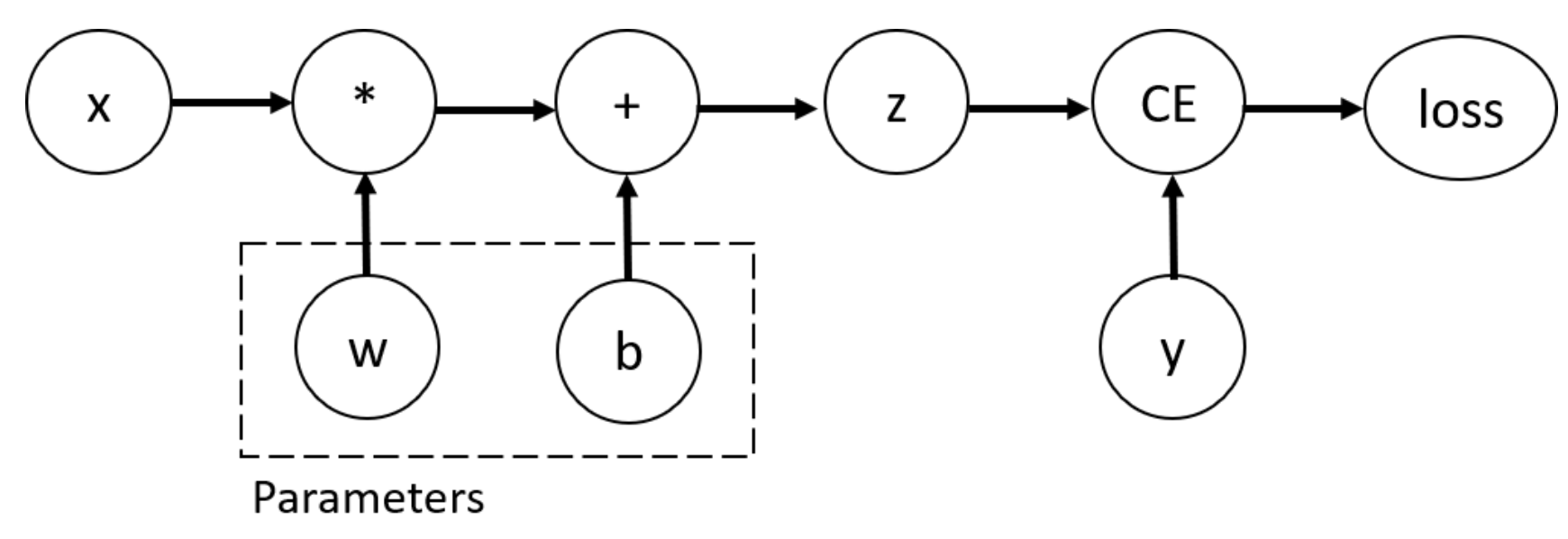
계산 그래프의 구성
이 코드 예제에서, `w`와 `b`는 최적화가 필요한 매개변수입니다. 따라서 손실 함수에 대한 이 매개변수들의 기울기를 계산할 수 있어야 합니다. 이를 위해 이 텐서들에 `requires_grad` 속성을 설정합니다.
import torch
# 매개변수 w와 b 초기화, requires_grad=True로 설정하여 기울기 계산 필요성 명시
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
`requires_grad` 속성은 텐서를 생성할 때 설정하거나, 나중에 `x.requires_grad_(True)` 메서드를 사용하여 설정할 수 있습니다.
Function 클래스
PyTorch에서 텐서에 적용되는 함수는 `Function` 클래스의 객체입니다. 이 객체는 순전파(forward pass)에서 함수를 계산하는 방법과 역전파(backward pass) 시에 그 미분을 계산하는 방법을 알고 있습니다. 텐서의 `grad_fn` 속성은 이 역전파 함수에 대한 참조를 저장합니다.
x = torch.ones(5) # 입력 텐서
y = torch.zeros(3) # 출력 텐서
z = torch.matmul(x, w) + b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
# z와 loss의 grad_fn 출력
print(f"Gradient function for z = {z.grad_fn}")
print(f"Gradient function for loss = {loss.grad_fn}")
출력된 `grad_fn`은 각 변수에 대해 수행된 마지막 연산을 나타냅니다. 예를 들어, `z`의 `grad_fn`은 행렬 곱셈과 덧셈을 수행하는 함수를, `loss`의 `grad_fn`은 로짓과 타깃 간의 바이너리 크로스 엔트로피 손실을 계산하는 함수를 나타냅니다.
이 정보를 통해 PyTorch가 어떻게 각 연산의 미분을 관리하고 계산 그래프를 통해 기울기를 효과적으로 전파하는지 이해할 수 있습니다.
기울기 계산하기
신경망의 매개변수 가중치를 최적화하려면, 손실 함수에 대한 매개변수의 도함수(기울기)를 계산해야 합니다. 즉, ∂loss/∂w 와 ∂loss/∂b를 계산해야 합니다. 이 기울기들을 계산하기 위해, `loss.backward()`를 호출한 다음, `w.grad`와 `b.grad`에서 값을 검색합니다.
기울기 계산 과정
다음은 간단한 신경망에서 손실 함수의 기울기를 계산하고 출력하는 과정을 보여주는 코드 예제입니다:
import torch
# 매개변수 초기화
x = torch.ones(5) # 입력 텐서
y = torch.zeros(3) # 예상 출력
w = torch.randn(5, 3, requires_grad=True) # 가중치
b = torch.randn(3, requires_grad=True) # 편향
# 순전파
z = torch.matmul(x, w) + b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
# 역전파: 기울기 계산
loss.backward()
# 기울기 출력
print("Gradient of w:")
print(w.grad)
print("Gradient of b:")
print(b.grad)
이 코드는 다음을 수행합니다:
1. 매개변수 초기화: `x`, `y`, `w`, `b`를 초기화합니다. `w`와 `b`는 `requires_grad=True`로 설정되어, 이 텐서들에 대한 기울기가 필요하다는 것을 PyTorch에 알립니다.
2. 순전파: 입력 `x`에 대해 선형 변환을 수행하고, 결과에 편향 `b`를 더합니다. 그리고 이 결과를 `binary_cross_entropy_with_logits` 손실 함수에 넣어 손실을 계산합니다.
3. 역전파 실행: `loss.backward()`를 호출하여 모든 매개변수(여기서는 `w`와 `b`)에 대한 손실 함수의 기울기를 계산합니다.
4. 기울기 출력: `w.grad`와 `b.grad`를 통해 계산된 기울기를 확인합니다.
출력되는 `w.grad`와 `b.grad`는 각 매개변수에 대한 손실 함수의 기울기를 나타냅니다. 이 값들은 매개변수를 업데이트할 때 사용되어, 학습 과정에서 손실을 최소화하는 방향으로 매개변수를 조정하는 데 도움을 줍니다. 이러한 기울기 계산은 신경망의 학습 과정에서 중심적인 역할을 합니다.
기울기 추적 비활성화하기
PyTorch는 `requires_grad=True`로 설정된 모든 텐서에 대해 기본적으로 계산 이력을 추적하고 기울기 계산을 지원합니다. 그러나 모델을 훈련한 후에는 단순히 입력 데이터에 적용만 하려는 경우처럼 기울기 계산이 필요 없는 상황도 있습니다. 이러한 경우, 네트워크를 통한 순전파 연산만 수행하고 싶을 때 기울기 추적을 중지할 수 있습니다.
기울기 추적 중지
`torch.no_grad()` 블록을 사용하여 코드를 감싸면 계산 추적을 중지할 수 있습니다. 이는 메모리 사용량을 줄이고 연산 속도를 향상시키는 데 도움이 됩니다. 다음은 이를 사용하는 예시입니다:
import torch
x = torch.ones(5)
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
# requires_grad=True 상태 확인
z = torch.matmul(x, w) + b
print(f"Before no_grad(), does z require gradients? {z.requires_grad}")
# no_grad() 블록 안에서의 연산은 기울기 추적을 하지 않음
with torch.no_grad():
z = torch.matmul(x, w) + b
print(f"After no_grad(), does z require gradients? {z.requires_grad}")
주의사항
1. 리프 노드의 기울기: 계산 그래프의 리프 노드(데이터를 입력받는 최초의 노드)만이 `requires_grad=True`가 설정된 경우, `grad` 속성을 갖습니다. 그 외의 노드는 기울기를 가지지 않습니다.
2. 한 번의 역전파 제한: 성능상의 이유로 주어진 그래프에 대해 `backward`를 한 번만 호출할 수 있습니다. 같은 그래프에 여러 번 `backward`를 호출해야 할 경우, `backward` 호출 시 `retain_graph=True`를 전달해야 합니다. 이는 그래프의 기울기가 계산된 후에도 그래프를 유지함을 의미합니다.
이러한 기능은 모델을 평가하거나 실제 운용 환경에서 모델을 사용할 때 유용하게 사용될 수 있으며, 필요하지 않은 기울기 계산을 방지하여 자원을 효율적으로 관리할 수 있습니다.
비활성화 이유 및 계산 그래프의 자세한 설명
기울기 추적 비활성화 이유
기울기 추적을 비활성화하는 이유는 여러 가지가 있습니다:
1. 모델의 일부 매개변수를 고정(frozen) 매개변수로 표시하고 싶을 때. 이는 전이 학습 같은 상황에서 유용하게 사용됩니다.
2. 순전파 연산만 수행할 때 계산 속도를 향상시키기 위해. 기울기를 추적하지 않는 텐서에 대한 연산이 더 효율적이기 때문입니다.
계산 그래프와 자동 미분
PyTorch의 `autograd`는 데이터(텐서)와 수행된 모든 연산(및 결과 텐서)을 담은 방향성 비순환 그래프(DAG)의 형태로 기록을 유지합니다. 이 DAG에서는 입력 텐서가 리프(leaf)이고, 출력 텐서가 루트(root)입니다. 루트에서 리프로 그래프를 추적하면, 체인 규칙을 사용하여 자동으로 기울기를 계산할 수 있습니다.
순전파 동안 `autograd`는 두 가지를 동시에 수행합니다:
- 요청된 연산을 수행하여 결과 텐서를 계산합니다.
- DAG 내에서 연산의 기울기 함수를 유지합니다.
`.backward()`가 DAG의 루트에 호출되면 역전파가 시작됩니다. `autograd`는:
- 각 `.grad_fn`에서 기울기를 계산합니다.
- 해당 텐서의 `.grad` 속성에 그 기울기를 누적합니다.
- 체인 규칙을 사용하여 리프 텐서까지 모든 기울기를 전파합니다.
주의할 점:
- PyTorch의 DAG는 동적입니다. `.backward()` 호출 후에는 그래프가 처음부터 다시 생성됩니다. 이는 모델에서 제어 흐름 문을 사용할 수 있게 해주며, 필요에 따라 각 반복마다 모양, 크기, 연산을 변경할 수 있습니다.
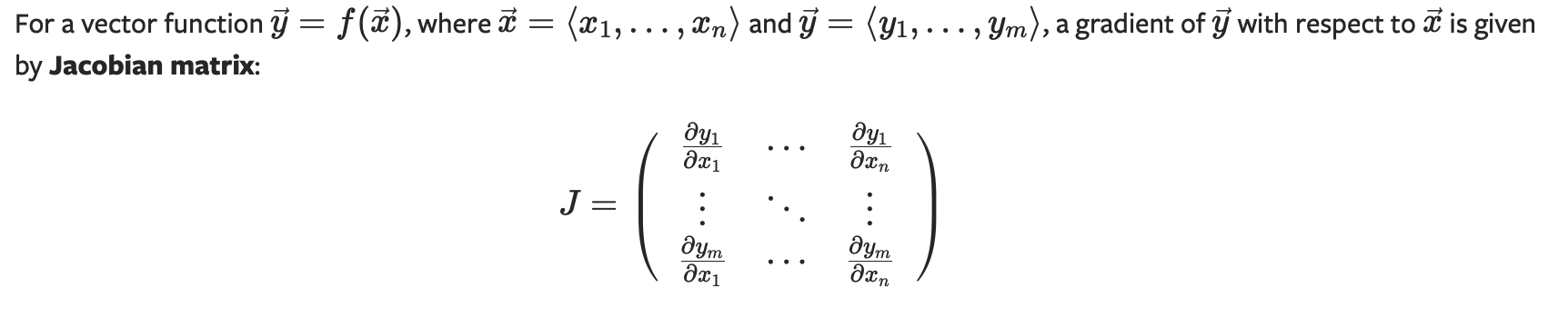
텐서 기울기와 Jacobian Products
종종 스칼라 손실 함수에 대해 매개변수의 기울기를 계산해야 하지만, 출력 함수가 임의의 텐서인 경우도 있습니다. 이 경우, PyTorch는 Jacobian 곱을 계산할 수 있게 해줍니다.
inp = torch.eye(4, 5, requires_grad=True)
out = (inp + 1).pow(2).t()
out.backward(torch.ones_like(out), retain_graph=True)
print(f"First call\n{inp.grad}")
out.backward(torch.ones_like(out), retain_graph=True)
print(f"\nSecond call\n{inp.grad}")
inp.grad.zero_()
out.backward(torch.ones_like(out), retain_graph=True)
print(f"\nCall after zeroing gradients\n{inp.grad}")
위 코드는 주어진 입력 벡터 .에 대해 Jacobian Product vT⋅J을 계산합니다. 이 곱은 `backward`를 호출할 때 `v`를 인수로 사용하여 수행됩니다. `v`의 크기는 원래 텐서의 크기와 같아야 합니다. `retain_graph=True` 옵션은 그래프를 유지하며 여러 번 `backward`를 호출할 수 있게 해줍니다.
기울기 축적과 초기화 이해
PyTorch에서 `.backward()` 함수를 호출하면, 연산 그래프의 리프 노드들에 대한 기울기가 계산되고 누적됩니다. 즉, 계산된 기울기 값은 리프 노드의 `grad` 속성에 추가됩니다. 이러한 특성은 신경망 훈련 중에 기울기를 여러 배치에 걸쳐 축적할 수 있게 하지만, 각 업데이트 사이클에서 기울기를 올바르게 계산하려면 `grad` 속성을 초기화할 필요가 있습니다.
기울기 축적 문제
`.backward()`를 여러 번 호출할 때 기울기가 축적되는 현상을 아래 예제를 통해 확인할 수 있습니다:
import torch
# 가중치 정의 및 초기화
w = torch.randn(2, 2, requires_grad=True)
# 가중치에 대한 연산 수행
y = w + 2
z = y * y * 3
out = z.mean()
# 첫 번째 역전파: 기울기 계산
out.backward()
print("Gradients after first backward call:")
print(w.grad)
# 두 번째 역전파: 기울기 계산
out.backward()
print("Gradients after second backward call:")
print(w.grad)
이 예제에서 `out.backward()`를 처음 호출하면 `w.grad`에 기울기가 저장됩니다. 두 번째 `backward()` 호출 때는 이전에 계산된 기울기에 새로 계산된 기울기가 더해집니다. 그 결과, 기울기 값이 예상보다 두 배가 되는 문제가 발생합니다.
기울기를 올바르게 계산하기
신경망 훈련에서 매 업데이트 사이클마다 기울기를 초기화하는 것이 중요합니다. 이는 옵티마이저가 처리해 줍니다:
# 옵티마이저 정의
optimizer = torch.optim.SGD([w], lr=0.01)
# 기울기 초기화
optimizer.zero_grad()
# 역전파 실행
out.backward()
# 매개변수 업데이트
optimizer.step()
이 과정을 반복함으로써, 각 반복에서 정확한 기울기를 계산하고 모델 매개변수를 적절하게 업데이트할 수 있습니다.
`backward()` 호출에 대한 참고 사항
`.backward()`를 인자 없이 호출하는 것은 `.backward(torch.tensor(1.0))`을 호출하는 것과 동일합니다. 이는 스칼라 값 함수(예: 훈련 중 손실)의 기울기를 계산할 때 유용합니다. 이 방법은 손실 함수가 스칼라 값일 때 역전파를 시작하기 위한 방법으로, 기울기가 필요한 모든 변수에 대해 자동으로 계산됩니다.
* 모든 내용은 PyTorch 공식문서 홈페이지 내용을 바탕으로 작성되었습니다.
'Deep learning' 카테고리의 다른 글
| 음악 생성 모델 - midi file 처리하기 (0) | 2024.05.26 |
|---|---|
| PyTorch로 구현하는 Optimization (0) | 2024.05.04 |
| PyTorch를 사용한 신경망 구축 (0) | 2024.05.04 |
| PyTorch 기초 (데이터, 모델, 학습, 저장) (0) | 2024.05.03 |
| 인공지능 인터뷰 준비 - 실제 받았던 질문들 (0) | 2024.01.23 |